{ Projects }
This project focuses on predicting bankruptcies among Polish companies using various classification models. Under the guidance of Prof. Ramin Mohammadi, the research explores logistic regression, Gaussian Naive Bayes, decision tree, and support vector machines.Predicting corporate insolvency is crucial for stakeholders and investors. The project delves into the evolution of bankruptcy prediction, exploring statistical techniques and contemporary approaches.
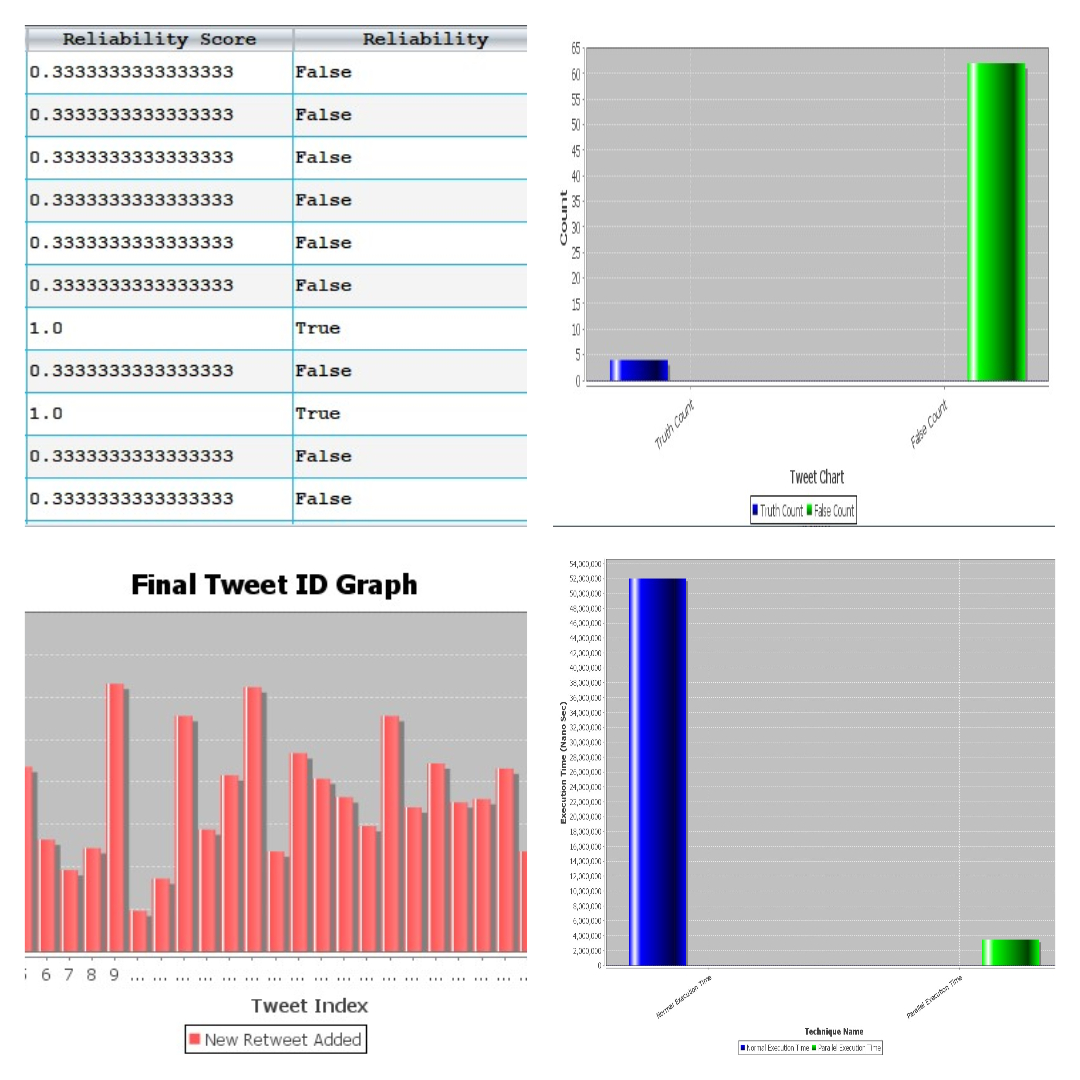
We solved the truth discovery problem, a rich set of principled approaches have been proposed in data mining, and network sensing communities. However, three important challenges have been well addressed for the existing truth discovery solutions in social media sensing applications. The Three important challenges (i.e., misinformation spread, data sparsity, and scalability) in solving the truth discovery problem in big data social media sensing applications
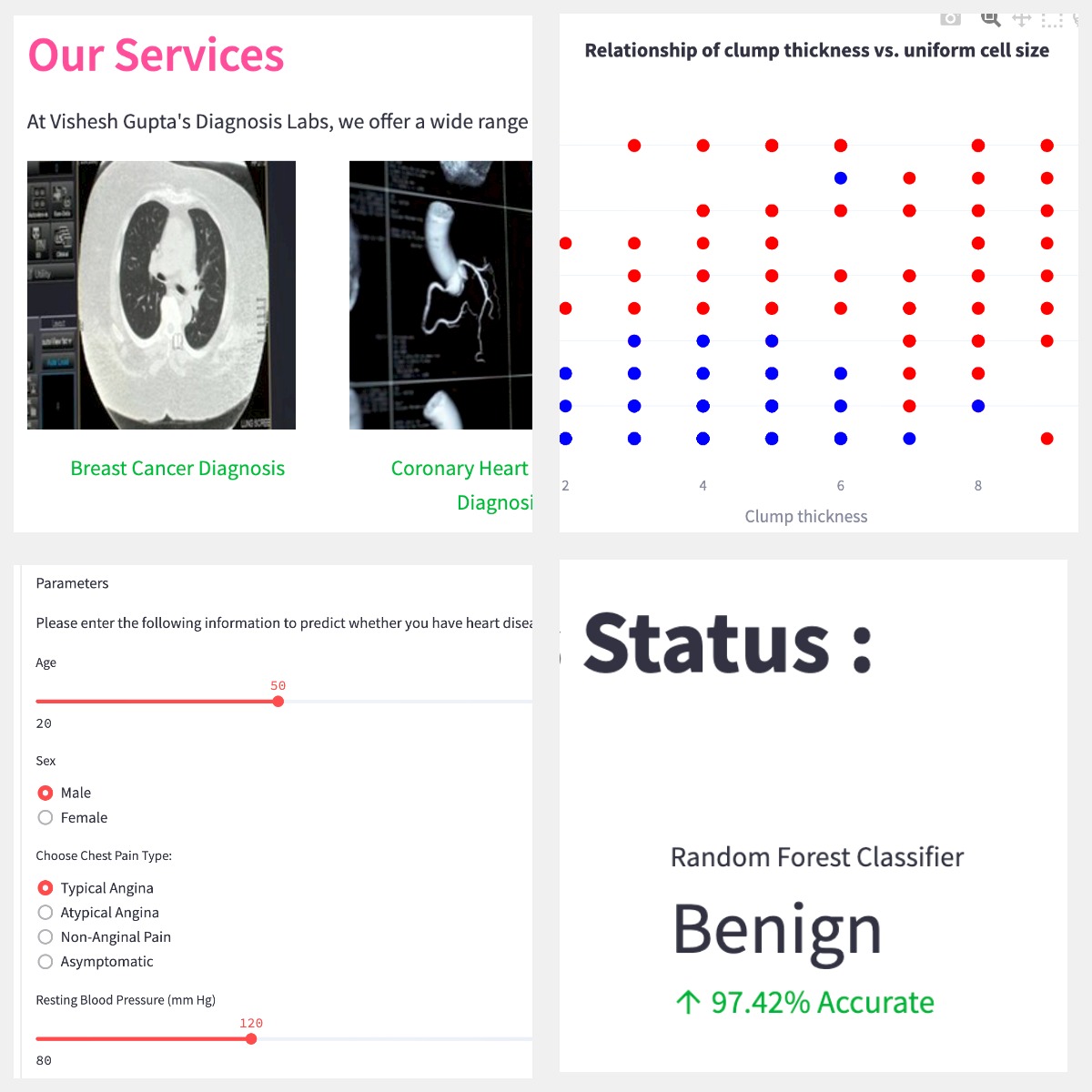
This is a web application that aims to help with the diagnosis of various diseases such as breast cancer, chronic kidney disease, coronary heart disease, liver disease, and diabetes mellitus by analyzing different parameters. The application employs machine learning models on the backend, which is a technique of integrating several ML models to provide accurate and reliable results.
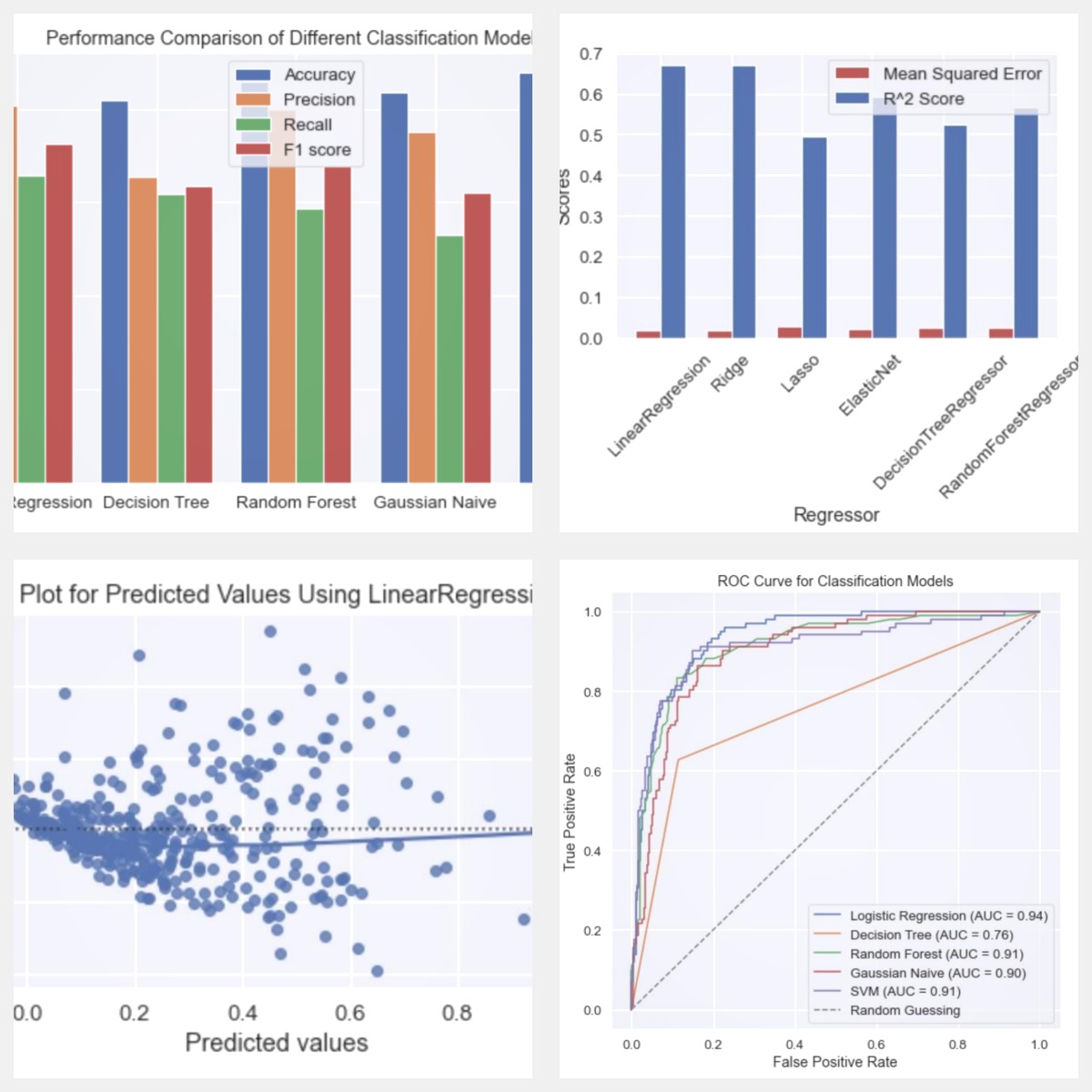
This project utilizes regression analysis and dimensional reduction techniques to predict crime rates in communities. By training the model on historical crime data, it can generate future crime rate predictions. The regression analysis incorporates socioeconomic indicators, demographic data, and geographical features to capture underlying patterns. Dimensional reduction techniques extract informative features, reducing complexity and improving predictive performance. The trained model allows users to input community data and receive crime rate predictions, enabling proactive measures for crime prevention and resource allocation.
We proposed a Heart Disorder Prediction System that would automatically identify whether or not a personsuffers from a heart disorder. The CHD analysis takes into account a number of heart predictions, such as the risk of heart attack and the likelihood of heart failure. We use the K-Nearest Neighbor, Random Forest, and Decision Tree models to make our predictions.
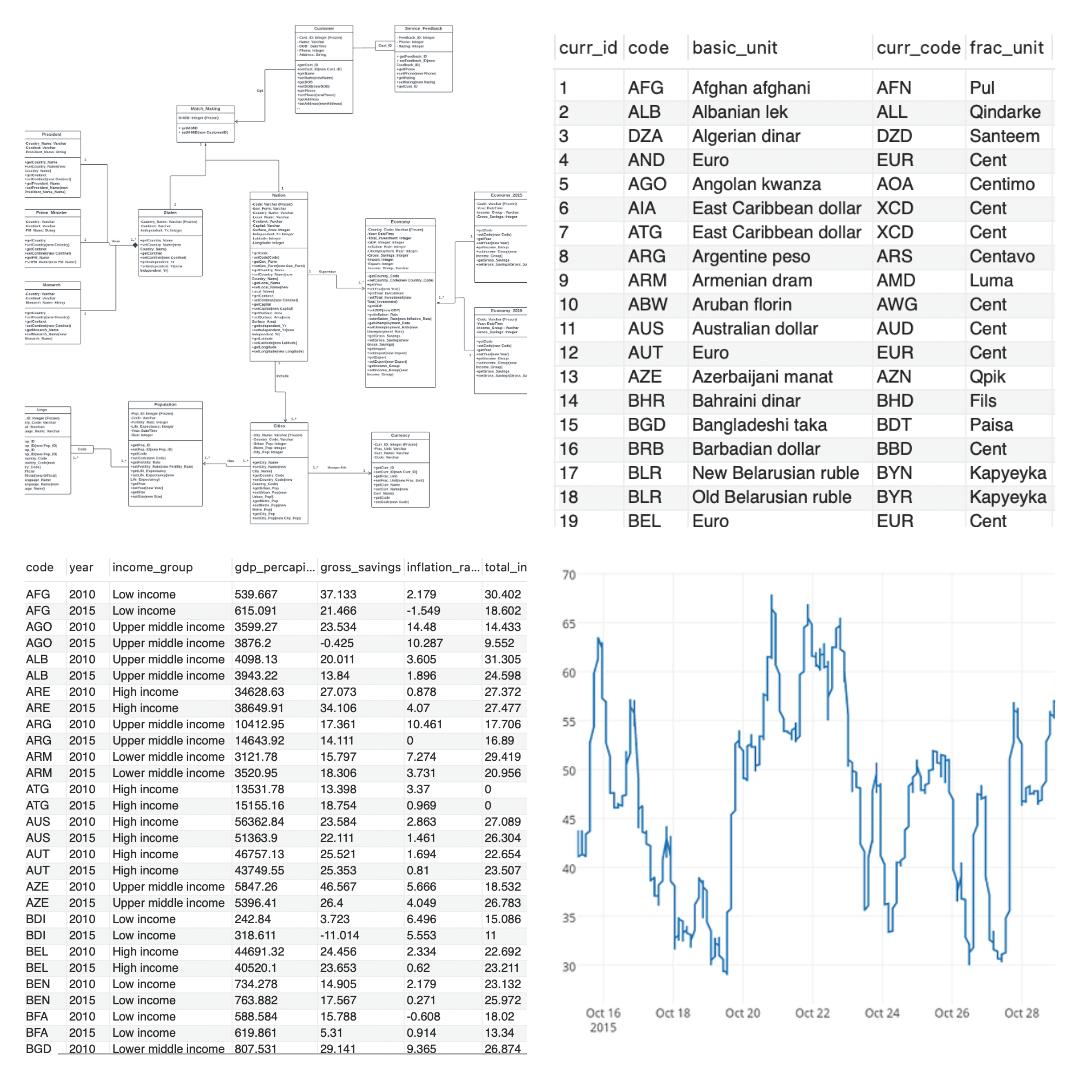
We designed a database for a consulting group using Entity Relationship Diagrams and the Relational Model. To ensure a robust and efficient database structure, we used advanced concepts such as aggregation, composition, and specialization. We created over a dozen tables for investment and tourism data using MySQL and MongoDB. We were able to conduct in-depth analytics and uncover trends in life expectancy, import and export, and fertility rates for the consulting group by connecting the database to the front end with Python.
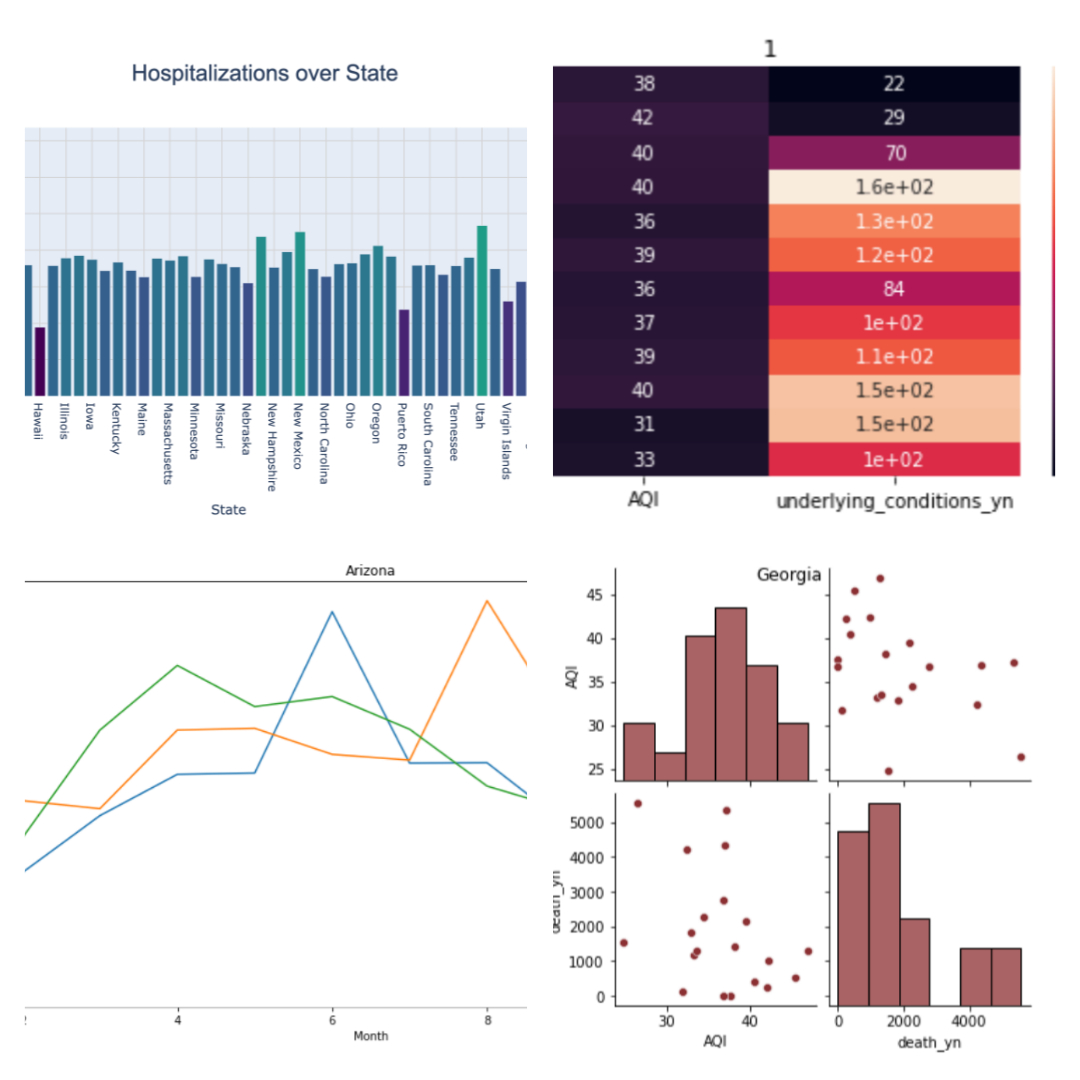
This project aims to study the relationship between air quality and the risk of COVID-19 hospitalization in the United States. The project uses two data sources: Air Quality Index (AQI) data from 1980 to 2021 and COVID-19 case surveillance data from 2020 to 2021. The study will use statistical methods and data visualization techniques to answer questions about the effect of lockdown on air quality, the correlation between AQI and COVID-19 hospitalization, controlling for confounding factors, and presentation of results.
We implemented an application domain with the purpose of managing unbalanced employee data and identifying new patterns of employee performance. We have applied Predictive Analytics to the dataframe in an effort to improve accuracy and reduce the number of false positives rate.
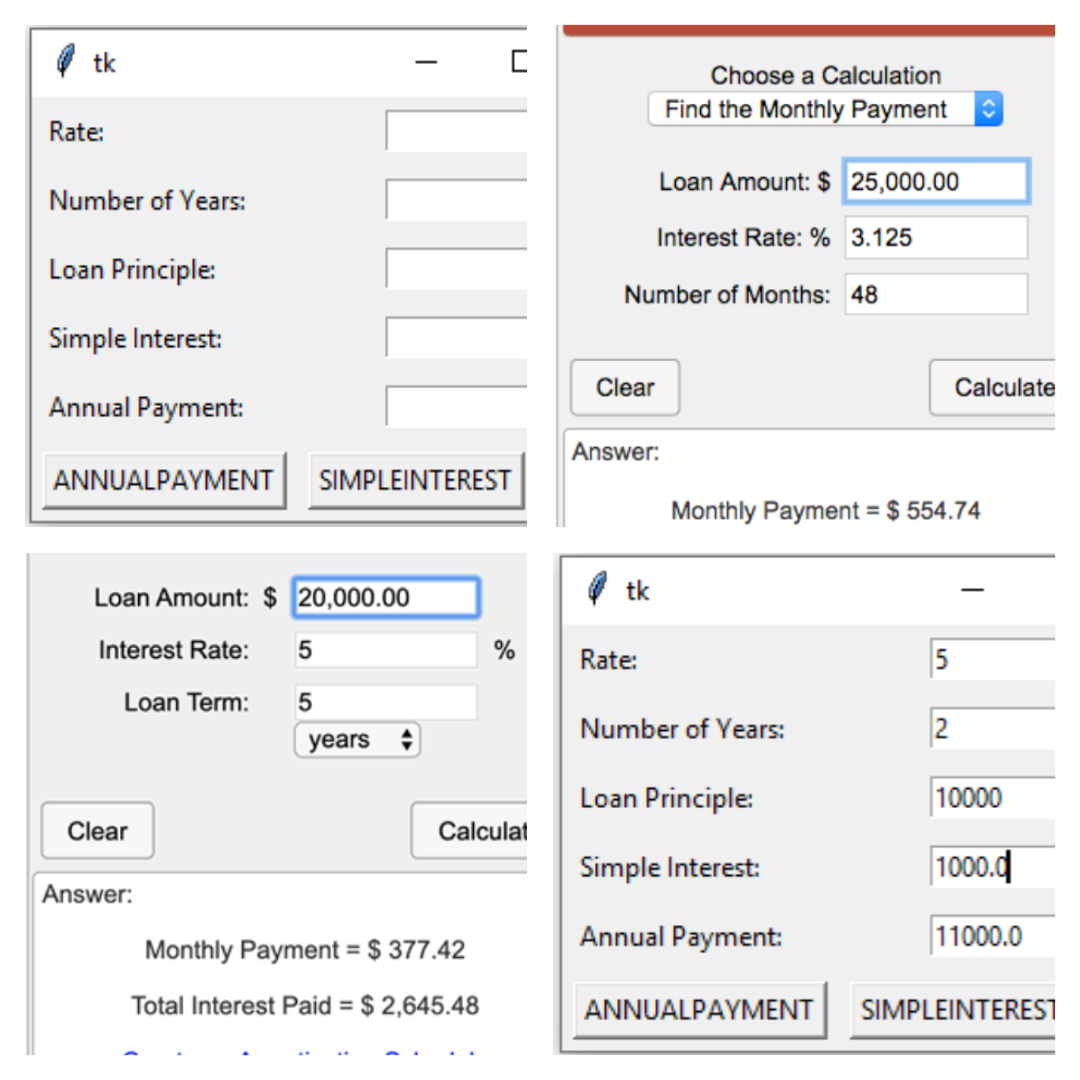
A Python application for calculating simple interest, annual payment, the rate of interest (ROI), and loan amount.